Prestazioni di sei chatbots di intelligenza artificiale rispetto alle linee guida di pratica clinica nel prendere decisioni informate per il dolore radicolare lombosacrale: uno studio trasversale
Comparative performance of six artificial intelligence chatbots in providing health advice for radicular lumbosacral pain against clinical practice guidelines: a cross-sectional study
Autori
Bargeri Silvia [IRCCS Istituto Ortopedico Galeazzi, Unit of Clinical Epidemiology, Milan, Italy]
Guida Stefania [IRCCS Istituto Ortopedico Galeazzi, Unit of Clinical Epidemiology, Milan, Italy]
Turolla Andrea [Department of Biomedical and Neuromotor Sciences (DIBINEM), Alma Mater University of Bologna, Bologna, Italy] [Unit of Occupational Medicine, IRCCS Azienda Ospedaliero-Universitaria di Bologna, Bologna, Italy]
Castellini Greta [IRCCS Istituto Ortopedico Galeazzi, Unit of Clinical Epidemiology, Milan, Italy]
Pillastrini Paolo [Department of Biomedical and Neuromotor Sciences (DIBINEM), Alma Mater University of Bologna, Bologna, Italy] [Unit of Occupational Medicine, IRCCS Azienda Ospedaliero-Universitaria di Bologna, Bologna, Italy]
Palese Alvisa [Department of Medical Sciences, University of Udine, Udine, Italy]
Cook Chad [Department of Orthopaedics, Duke University, Durham, NC] [Duke Clinical Research Institute, Duke University, Durham, NC] [Department of Population Health Sciences, Duke University, Durham, NC]
Rossettini Giacomo [School of Physiotherapy, University of Verona, Verona, Italy] [Department of Human Neurosciences, University of Rome ‘Sapienza Roma’, Rome, Italy] [Musculoskeletal Pain and Motor Control Research Group, Faculty of Sport Sciences, Universidad Europea de Madrid, 28670 Madrid, Spain] [Musculoskeletal Pain and Motor Control Research Group, Faculty of Health Sciences, Universidad Europea de Canarias, Tenerife, 38300 Canary Islands, Spain]
Gianola Silvia [IRCCS Istituto Ortopedico Galeazzi, Unit of Clinical Epidemiology, Milan, Italy]
Introduction
Large Language Models (LLMs) are advanced deep learning systems designed to understand, generate, and interact with human language. In the field of LLMs, artificial intelligence (AI) chatbots represent emerging tools that are trained to generate human-like text based on large amounts of data. This technological advancement is particularly significant in healthcare, where patients increasingly rely on AI chatbots for information on health conditions, treatment options, and preventive measures, essentially serving as virtual assistants. Specifically, for musculoskeletal pain conditions of the lumbar spine, the performance of AI chatbots in aligning with clinical practice guidelines (CPGs) for providing answers to complex clinical questions on lumbosacral radicular pain is still unclear.
Methods
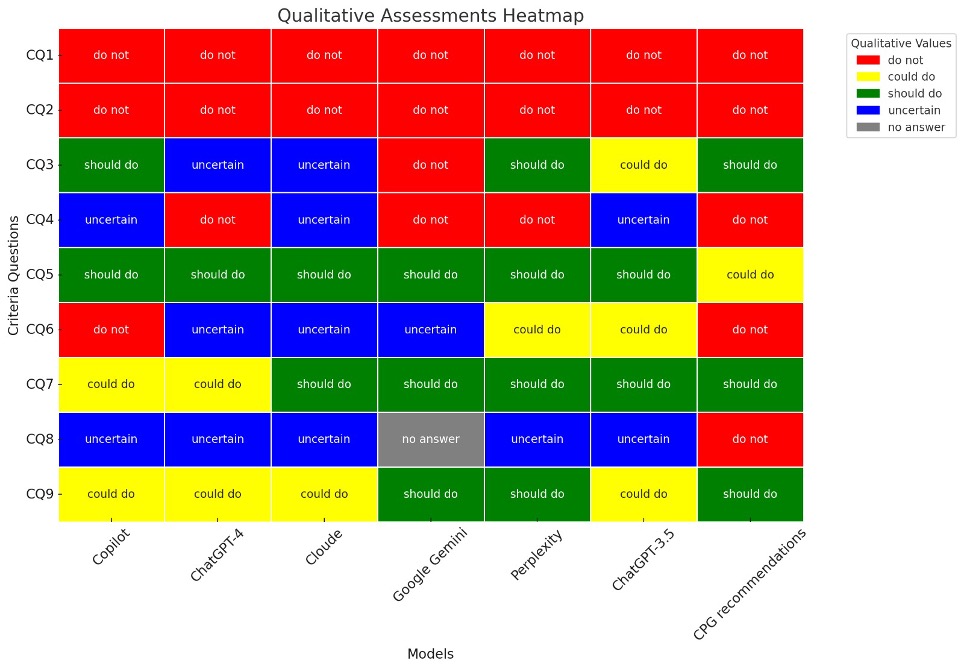
We conducted a cross-sectional study evaluating AI chatbots’ responses against CPGs recommendations for diagnosing and treating lumbosacral radicular pain. Eligible recommendations were extracted from a previous systematic review of CPGs and were categorized into ‘should do’, ‘could do’, ‘do not do’, or ‘uncertain’. Clinical questions derived from these CPGs were posed to the latest versions (updated in April 2024) of the following six AI chatbots: ChatGPT-3.5, ChatGPT-4, Microsoft Copilot, Google Gemini, Claude, and Perplexity. We assessed the AI chatbots performance by (i) measuring the internal consistency of their answers through the percentage of text similarity when a question was re-asked for three times, (ii) evaluating the reliability between two independent reviewers in grading chatbots responses using Fleiss’ kappa coefficients and (iii) comparing the accuracy of AI chatbots answers to CPG recommendations, determined by the frequency of agreement among all judgments.
Results
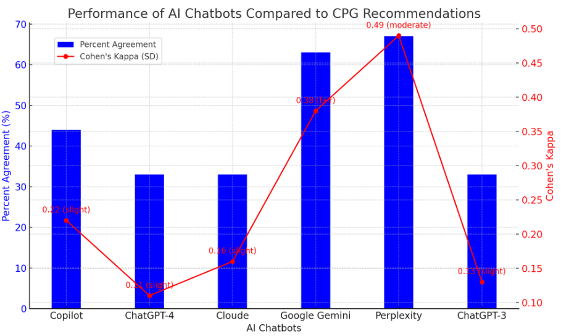
Nine clinical questions were tested. Overall, we found highly variable internal consistency in the responses from chatbots for each question (median range 26% to 68%). The intra-rater reliability was “almost perfect” for both reviewers in Copilot, Perplexity, and ChatGPT-3.5, and “substantial” in ChatGPT-4, Claude, and Gemini. Inter-rater reliability was “almost perfect” in Perplexity (0.84, SE: 0.16) and ChatGPT-3.5 (0.85, SE: 0.15), “substantial” in Copilot (0.69, SE: 0.20), Claude (0.66, SE: 0.21), and Google Gemini (0.80, SE: 0.18), and “moderate” for ChatGPT-4 (0.54, SE: 0.23). Compared to CPGs recommendations, Perplexity had the highest accuracy (67%), followed by Google Gemini (63%) and Copilot (44%). Conversely, Claude, ChatGPT-3.5, and ChatGPT-4 showed the lowest, each scoring 33% (Figure 1 and 2).
Discussion and Conclusion
Despite the variability in internal consistency and good intra- and inter-rater reliability, the AI chatbots’ responses often did not align with CPGs recommendations for diagnosing and treating lumbosacral radicular pain. Clinicians and patients should pay attention when using these AI models, since one-third to two-thirds of the recommendations provided may be inappropriate or misleading according to specific chatbots.
REFERENCES
Clusmann J, Kolbinger FR, Muti HS, et al. The future landscape of large language models in medicine. Commun Med. 2023;3(1):141. doi:10.1038/s43856-023-00370-1
Park YJ, Pillai A, Deng J, et al. Assessing the research landscape and clinical utility of large language models: a scoping review. BMC Med Inform Decis Mak. 2024;24(1):72. doi:10.1186/s12911-024-02459-6
Khorami AK, Oliveira CB, Maher CG, et al. Recommendations for Diagnosis and Treatment of Lumbosacral Radicular Pain: A Systematic Review of Clinical Practice Guidelines. J Clin Med 2021; 10(11).
Norman GR, Streiner DL. Biostatistics: The Bare Essentials. People’s Medical Publishing House; 2014.