Is artificial intelligence reliable in assessing the internal validity of the randomized controlled trial in physiotherapy? A cross-sectional study
Autori
Giacomo Perugino – (Program in Physical Therapy, University of Florence, Florence, Italy)
Camilla De Pedrini – (UniCamillus, International Medical University in Rome, Rome, Italy)
Daniele Piscitelli – (School of Medicine and Surgery, University of Milano-Bicocca, Monza, Italy)
Alessandro Ugolini – (Independent researcher, Empoli (FI), Italy)
Alessandra Carlizza – (UniCamillus, International Medical University in Rome, Rome, Italy)
Leonardo Pellicciari (IRCCS Istituto delle Scienze Neurologiche di Bologna, Bologna, Italy)
Background and aims
Artificial intelligence (AI) is defined as the ability of computer systems to perform tasks that would traditionally require human intelligence. Its application is widespread in physiotherapy science, supporting procedures such as gait analysis and diagnostic image interpretation.
A crucial aspect of the critical appraisal in the evidence-based practice is assessing the internal validity of randomized clinical trials (RCTs) to ensure the reliability of results. Among instruments assessing the internal validity, the PEDro scale is used to evaluate the internal validity of RCTs.
This study aims to evaluate the reliability and agreement of ChatGPT (i.e., a generative AI) in assigning the PEDro score by comparing AI-generated scores with human scores.
Methods
Artificial intelligence (AI) is defined as the ability of computer systems to perform tasks that would traditionally require human intelligence. Its application is widespread in physiotherapy science, supporting procedures such as gait analysis and diagnostic image interpretation.
A crucial aspect of the critical appraisal in the evidence-based practice is assessing the internal validity of randomized clinical trials (RCTs) to ensure the reliability of results. Among instruments assessing the internal validity, the PEDro scale is used to evaluate the internal validity of RCTs.
This study aims to evaluate the reliability and agreement of ChatGPT (i.e., a generative AI) in assigning the PEDro score by comparing AI-generated scores with human scores.
Results
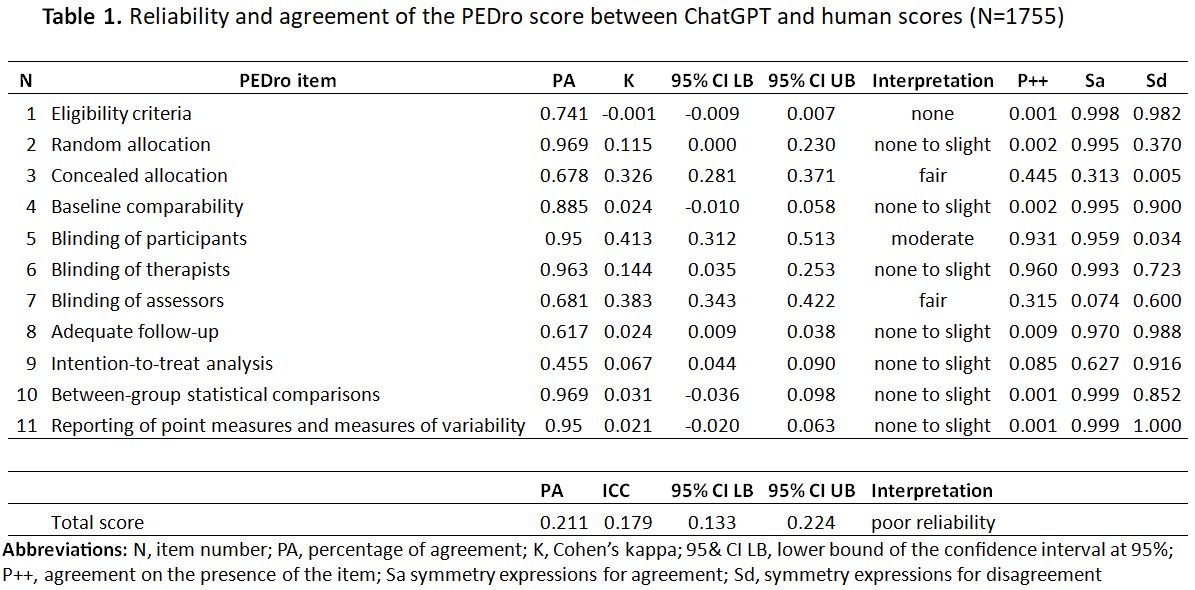
1755 RCTs were included. The percentage of agreement ranged between 67.8% (Item#3) and 96.9% (Item#2 and Item#10). The k values were below 0.450, indicating slight to moderate reliability; however, these findings are influenced by the k paradox (i.e., higher percentage of agreement but lower k, consequent to the heterogeneity in the rating). P++ findings showed that the two assessors attributed few simultaneous “yes” responses, while the SA indicates that the concordance is mainly reported in “yes” responses, while the SD showed that one evaluator tends to say “yes” more than the other. Finally, the ICC for the total score indicates poor inter-rater reliability. Similar recurrent result patterns are reported for the analyses of the subcategories.
Conclusion
Our results show variability in agreement between ChatGPT and human reviewers depending on the items considered. Items with high agreement are related to the presence in the full texts of keywords recognizable by AI, while more complex items that require cognitive reasoning (i.e., Item#9). To date, ChatGPT could be used as a preliminary screening tool to assess certain PEDro items, but it cannot replace human assessment.
REFERENCES
Cashin AG, McAuley JH. Clinimetrics: Physiotherapy Evidence Database (PEDro) Scale. J Physiother. 2020 Jan;66(1):59. doi: 10.1016/j.jphys.2019.08.005.
Maher CG, Sherrington C, Herbert RD, Moseley AM, Elkins M. Reliability of the PEDro scale for rating quality of randomized controlled trials. Phys Ther. 2003 Aug;83(8):713-21.